Extracting Metrics and Preparing Data for Analysis
Several metrics can be used in culturomics research for quantitative analysis of content and engagement with digital corpora, both in absolute (count) or relative (frequency) terms. These metrics may be obtained from elements of corpora content and engagement, including volume, context, and interest. Many are also readily available to researchers in raw or pre-analyzed
formats including, for example, Wikipedia page edits, internet search volume, or YouTube video comments. However, metrics relating specifically to the content of digital corpora often need to be extracted from the corpus after data are collected. Recent advances in machine learning methods, namely, in computer vision and natural language processing, have greatly facilitated
content analysis for large volumes of texts and images. Using natural language processing approaches, such as named entity recognition or sentiment analysis, allows the extraction of quantitative information on entities mentioned in texts and the sentiments expressed in relation to them. Similarly, using computer vision algorithms permits the identification and
quantification of elements and sentiments expressed in images. Similar methods are being developed for sound and video data and are likely to become widespread in the near future, thus facilitating the large-scale analyses of these data formats.
More information on data pre-processing and culturomics metrics can be found in Corriea et al. 2021.
formats including, for example, Wikipedia page edits, internet search volume, or YouTube video comments. However, metrics relating specifically to the content of digital corpora often need to be extracted from the corpus after data are collected. Recent advances in machine learning methods, namely, in computer vision and natural language processing, have greatly facilitated
content analysis for large volumes of texts and images. Using natural language processing approaches, such as named entity recognition or sentiment analysis, allows the extraction of quantitative information on entities mentioned in texts and the sentiments expressed in relation to them. Similarly, using computer vision algorithms permits the identification and
quantification of elements and sentiments expressed in images. Similar methods are being developed for sound and video data and are likely to become widespread in the near future, thus facilitating the large-scale analyses of these data formats.
More information on data pre-processing and culturomics metrics can be found in Corriea et al. 2021.
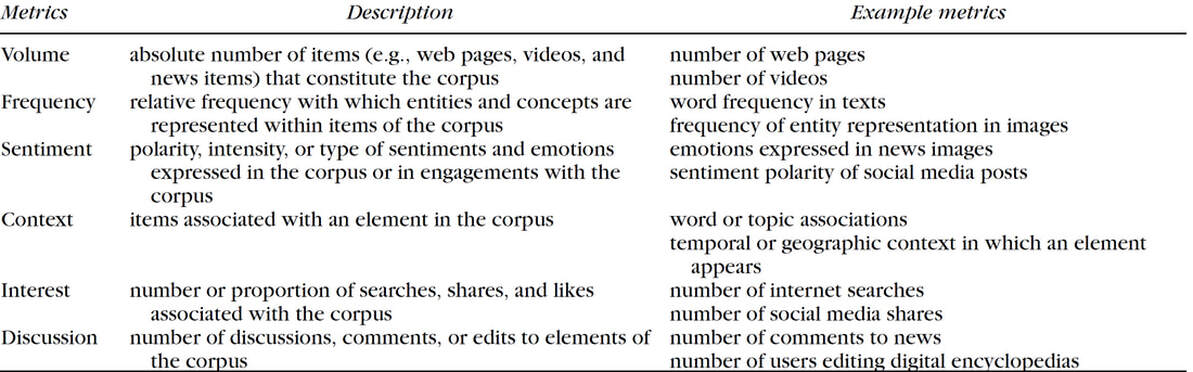
Examples of metrics of corpus content and engagement commonly used in culturomics research

